¿Es realmente efectivo tu modelo de clasificación de machine learning o simplemente un chepazo? La función confusionMatrix() del paquete caret tiene la respuesta. La mayoría de las personas solo se fijan en la precisión y luego pasan directamente a la sensibilidad, especificidad y valores predictivos, pero a menudo pasan por alto los conceptos fundamentales: la tasa de información nula (No Information Rate), el Kappa y los valores P (P-values).
Las primeras métricas en la matriz de confusión:
Figura 1: Resultados de confusionMatrix()
es lo que importa, y aquí está lo interesante: no son simples rellenos. Los expertos en machine learning avanzado saben que son esenciales para evaluar la confiabilidad de un modelo. Por eso están en la parte superior de la matriz de confusión. Vamos a sumergirnos en estas métricas que se pasan por alto y mostrar cómo se diferencian a los profesionales de los amateurs.
No Information Rate (Tasa de Información Nula)
Es la precisión que obtendrías si siempre predecías la clase mayoritaria. ¿Por qué importa la tasa de información nula? Porque una alta precisión puede ser engañosa, especialmente con conjuntos de datos desequilibrados. Por ejemplo, si el \(90\%\) de tus datos pertenece a una clase, un modelo que siempre (el \(100\%\) de las veces) prediga esa clase tendrá un \(90\%\) de precisión, aunque en realidad no sea inteligente. La tasa de información nula te ayuda a verificar si tu modelo es genuinamente mejor que este simple baseline.
La tasa de información nula se calcula como la proporción de la clase más frecuente en el conjunto de datos. Para nuestro caso:
\[
NIR=\frac{Subidas}{Total}
\]
\[
NIR=\frac{(108+2253)}{Total}
\]
Una tasa de información nula del \(64.74\%\) significa que si siempre predecimos la clase mayoritaria (resultado subida en nuestro ejemplo), lograríamos una precisión del \(64.74\%\). La precisión de nuestro modelo es del \(93.36\%\), que es mucho mayor que la tasa de información nula, lo que muestra que nuestro modelo funciona mucho mejor que un clasificador trivial.
La mejora de \(93.36\% - 64.74\% = 28.62\%\) puntos demuestra que nuestro modelo agrega un valor real más allá de simplemente predecir la clase mayoritaria. Pero ¿cómo sabemos que esta mejora es estadísticamente significativa? Buena pregunta, y eso es exactamente lo que nos dice la métrica P.
P-Value (Valor P)
El valor P nos ayuda a determinar si la precisión de nuestro modelo es significativamente mejor que la que lograríamos simplemente predecir la clase más frecuente. El valor P se calcula utilizando una prueba binomial de una cola, que compara la precisión observada del modelo \((0.9336)\) con la tasa de información nula que acabamos de calcular.
binom.test(x =1152+2253, # x - número de clasificaciones correctasn =108+134+1152+2253, # n - número de intentosp =0.6474, # p - probabilidad esperada de éxito,alternative ="greater")
Exact binomial test
data: 1152 + 2253 and 108 + 134 + 1152 + 2253
number of successes = 3405, number of trials = 3647, p-value < 2.2e-16
alternative hypothesis: true probability of success is greater than 0.6474
95 percent confidence interval:
0.926466 1.000000
sample estimates:
probability of success
0.9336441
Aquí está cómo interpretarlo: la hipótesis nula asume que la precisión del modelo no es mayor que la tasa de información nula, y la hipótesis alternativa establece que la precisión del modelo es mayor que la tasa de información nula. Si el valor \(P<0.05\), rechazamos la hipótesis nula. Esto significa que la precisión del modelo es significativamente mejor que la tasa de información nula, lo que demuestra que agrega valor más allá de simplemente predecir la clase mayoritaria. Pero si el valor \(P \ge 0.05\), no rechazamos la hipótesis nula. Esto sugiere que la precisión del modelo no es significativamente mejor que la tasa de información nula, lo que indica que podría no funcionar significativamente mejor que un clasificador ingenuo.
Null Error Rate (Tasa de Error Nula)
La tasa de error nula es similar a la tasa de información nula, pero en lugar de precisión, se expresa como una tasa de error. Muestra la tasa de error si siempre predijéramos la clase mayoritaria. Esto nos da una línea base para ver si nuestro modelo está reduciendo realmente los errores en comparación con una estrategia ingenua.
La tasa de error nula es especialmente útil para conjuntos de datos desequilibrados, donde la clase mayoritaria domina y la precisión sola puede ser engañosa. La tasa de error nula es simplemente la proporción de la clase minoritaria en el conjunto de datos.
\[
NER=\frac{Bajadas}{Total}
\]
\[
NER=1-NIR
\]
Por ejemplo, si la clase minoritaria tiene \(1152+134=1286\) casos positivos de un total de \(3647\), siempre predecir la clase mayoritaria resultaría en \(1286\) predicciones incorrectas.
Una tasa de error nula del \(35.26\%\) significa que si siempre predijéramos la clase mayoritaria, estaríamos equivocados el \(35.26\%\) de las veces. Esto nos da una referencia clara para evaluar el rendimiento del modelo. Y aquí está la razón: un buen modelo debería tener una tasa de error significativamente menor que esa línea base.
Nuestro modelo tiene una tasa de error del \(1-0.9336=6.64\%\), mucho menor que el \(35.26\%\) de la tasa de error nula. Pero ¿cómo probamos que esta diferencia es estadísticamente significativa? Al igual que con el valor P anterior, utilizamos una prueba binomial de una cola para verificar si la tasa de error del modelo es significativamente menor que la tasa de error nula.
binom.test(x =108+134, # x - número de clasificaciones correctasn =108+134+1152+2253, # n - número de intentosp =0.3526, # p - probabilidad esperada de éxito,alternative ="less"# probar que es significativamente menor que NER)
Exact binomial test
data: 108 + 134 and 108 + 134 + 1152 + 2253
number of successes = 242, number of trials = 3647, p-value < 2.2e-16
alternative hypothesis: true probability of success is less than 0.3526
95 percent confidence interval:
0.00000000 0.07353402
sample estimates:
probability of success
0.06635591
En esta prueba, la hipótesis nula asume que la tasa de error del modelo \((6.64\%)\) no es diferente de la tasa de error nula \((35.26\%)\). Dado que el valor P es inferior a 0.05, rechazamos la hipótesis nula y concluimos que la tasa de error del modelo es significativamente menor que la tasa de error nula.
Entonces, la tasa de error nula nos ayuda a confirmar si un modelo está reduciendo verdaderamente el error en comparación con simplemente predecir la clase mayoritaria. Mientras que la función confusionMatrix() verifica si la precisión es significativamente mayor que la tasa de información nula, la tasa de error nula ofrece una visión complementaria al evaluar si la tasa de error es significativamente menor que la baseline ingenua. Juntas, estas métricas proporcionan una comprensión más profunda del rendimiento del modelo. Mientras que la tasa de información nula y la tasa de error nula resaltan cuán mejor o peor es tu modelo en comparación con una baseline ingenua, la estadística Kappa va un paso más allá, ya que mide el acuerdo entre las clasificaciones observadas y las predichas. Por lo tanto, debemos hablar sobre Kappa.
Kappa
La estadística Kappa nos dice cuán bien coinciden las clasificaciones observadas y predichas, ajustando por el acuerdo que podría ocurrir por casualidad. Esto la hace especialmente útil al lidiar con conjuntos de datos desequilibrados o múltiples clases, donde la precisión sola podría ser engañosa.
La escala de interpretación comúnmente aceptada indica que un Kappa de +1 significa un acuerdo perfecto, cero es no mejor que una suposición aleatoria, y un Kappa negativo es peor que una suposición aleatoria.
\(<0:\) No acuerdo.
\(0 - 0.2:\) Ligero acuerdo.
\(0.41 - 0.60:\) Moderado acuerdo.
\(0.61 - 0.80:\) Sólido acuerdo.
\(0.81 - 1:\) Casi perfecto acuerodo.
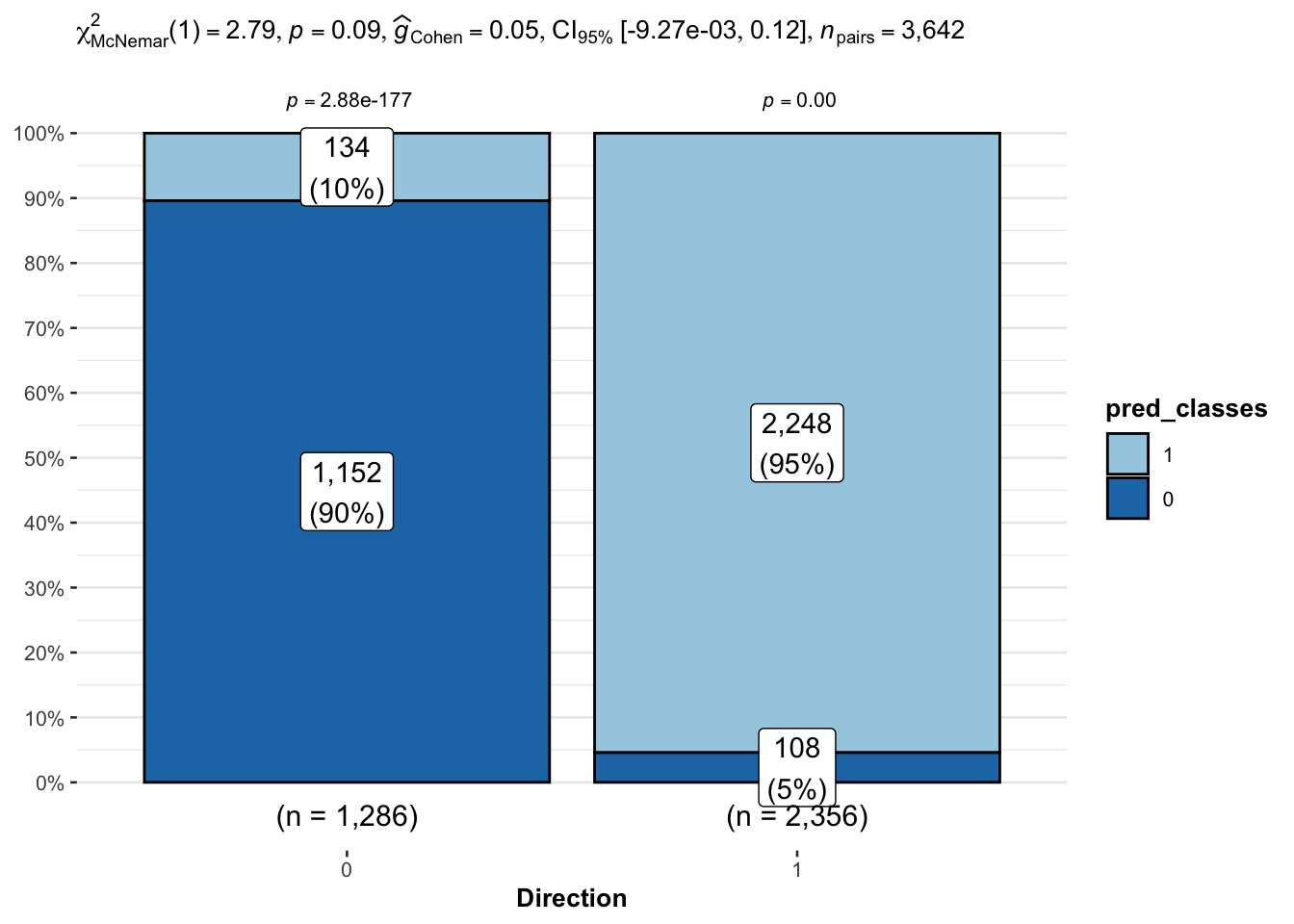
Nuestro Kappa de \(0.845\) muestra un acuerdo sólido entre las clasificaciones observadas y predichas. Y aunque saber que el acuerdo es revelador, por sí solo no nos dice si ese acuerdo es estadísticamente significativo, es ahí donde entra en juego el valor de prueba de McNemar.
McNemar Test (Prueba de McNemar)
La prueba de McNemar nos dice si las discrepancias entre las predicciones del modelo y los resultados reales son estadísticamente significativas o simplemente debido a fluctuaciones aleatorias en los datos. Mientras que métricas como precisión, exactitud y cobertura proporcionan una evaluación general, no se enfocan en dónde el modelo se equivoca. La prueba de McNemar se centra específicamente en esas discrepancias, mostrando si los errores son ruido aleatorio o si el rendimiento del modelo es realmente confiable.
library(myfinance)library(caret)# Función para calcular los resultados tanto de train como de testcalculate_results <-function(model, data) {# Realizar predicción predictions <-predict(model, data)# Convertir predicciones en probabilidades probabilities <-1/ (1+exp(-predictions))# Determinar la dirección basada en el umbral de 0.5 direction <-ifelse(probabilities >0.5, 1, 0)# Crear la matriz de confusión confusion <-confusionMatrix(factor(direction), factor(data$Direction), mode ="everything")# Devolver los resultadoslist(predicted_direction = direction,confusion_matrix = confusion,predictions = predictions )}# Ejecutar el análisis principalmodelo <-main_analysis()
[1] "Iniciando el análisis principal..."
[1] "Cargando datos..."
[1] "Datos cargados exitosamente. Número de filas: 4594"
[1] "Creando variables predictoras..."
[1] "Variables predictoras creadas exitosamente."
[1] "Creando tabla de datos..."
[1] "Tabla de datos creada exitosamente."
[1] "Dividiendo datos en train y test..."
[1] "Datos divididos exitosamente. Train: 3675 Test: 919"
[1] "Normalizando datos..."
[1] "Normalizados"
[1] "Datos normalizados exitosamente."
[1] "Construyendo y entrenando el modelo..."
[1] "Modelo construido y entrenado exitosamente."
[1] "Haciendo predicciones para train..."
[1] "Predicciones para train completadas."
[1] "Evaluando modelo en train..."
[1] "Evaluación en train:"
[1] "Haciendo predicciones para test..."
[1] "Predicciones para test completadas."
[1] "Evaluando modelo en test..."
[1] "Evaluación en test:"
[1] "Análisis completado exitosamente."
[1] "Proceso finalizado."
Un valor P pequeño (menor que 0.05) indica una diferencia estadísticamente significativa entre las predicciones del modelo y los valores reales. En términos sencillos, el modelo no está incurriendo en errores aleatorios; hay un patrón en sus errores. Por ejemplo, podría estar consistentemente equivocado en ciertas situaciones, lo que nos dice que los errores no ocurren por casualidad.
En nuestro ejemplo, el modelo tiene un número mayor de falsos negativos \((134)\) en comparación con los falsos positivos \((108)\). Esto significa que el modelo es más probable que omita casos positivos reales que clasifique incorrectamente como positivos a los casos negativos. ¿Por qué esto importa? Este patrón es crucial en contextos donde omitir casos positivos es más grave que identificar incorrectamente a los negativos, como en diagnósticos médicos.
Por ejemplo, perder un diagnóstico de cáncer (falso negativo) puede ser más dañino que un falso aviso (falso positivo), pero ¿qué podemos hacer para mejorar el rendimiento del modelo? Ajustar el umbral para reducir los falsos negativos podría ayudar.
Un valor P grande (mayor que 0.05) es lo que queremos, ya que sugiere que las discrepancias entre las predicciones y los valores reales son probablemente debido al azar, y no hay evidencia sólida de que el modelo esté making errores sistemáticos. En resumen, un valor P pequeño indica algo que vale la pena investigar, mientras que un valor P grande nos dice que el modelo está bien.
La prueba de McNemar no solo compara los valores reales con las predicciones, sino que también puede comparar dos clasificadores si necesitas saber cuál es mejor. Y dado que comparar clasificadores estadísticamente es crucial para cualquier experto serio en machine learning, absolutamente necesitas sumergirte en la prueba de McNemar.
Cómo citar
BibTeX
@online{chiquito_valencia2025,
author = {Chiquito Valencia, Cristian},
title = {El Poder de Las Métricas: {Guía} Avanzada En {ML}},
date = {2025-04-27},
url = {https://cchiquitovalencia.github.io/posts/2025-04-27-predictions_on_stocks6/},
langid = {en}
}