── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ tibble::has_name() masks selenider::has_name()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(RSelenium)# Definimos la página para extraer los datosurl <-"https://www.cartlow.com/uae/en/q"withr::deferred_clear()# En nuestra sesión permitiremos 30 segundos# session <- selenider_session(# "selenium",# browser = "firefox",# timeout = 30,# .env = rlang::caller_env(),# view = FALSE,# quiet = TRUE# )
Definimos las funciones que nos ayudarán para el scraping:
Code
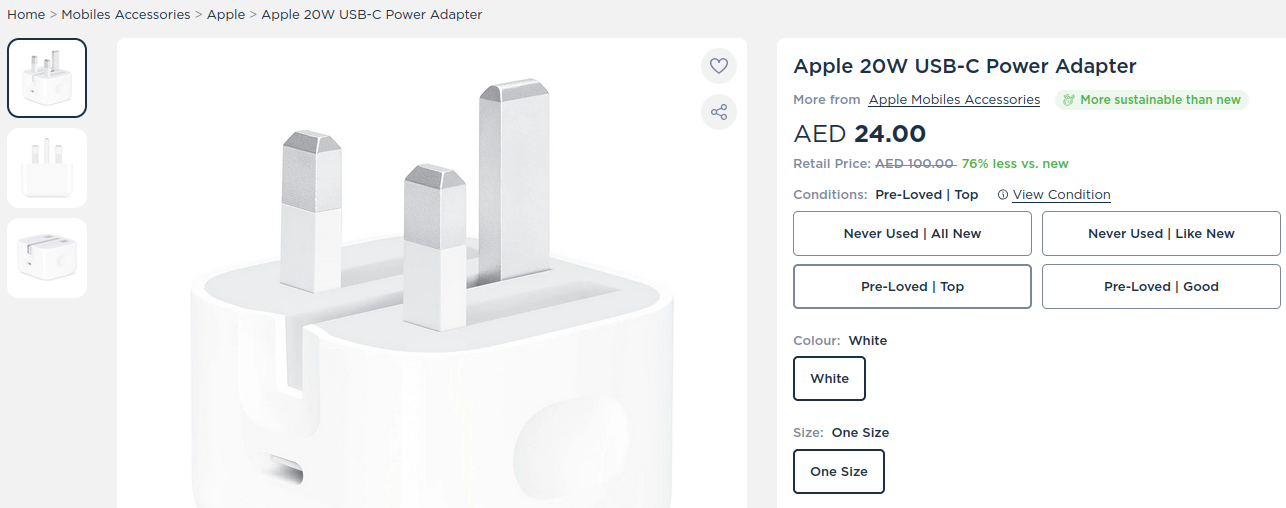
extraer_botones <-function(boton){ desc_botones <- boton |> purrr::map(~ .x |> purrr::map(~ .x$class)) |>unlist() desc_botones <-gsub("active", "", desc_botones)return(list(iter_botones = desc_botones))}extrae_imagenes <-function(producto){ mostrando <-s(".cz-thumblist-holder.sm-scrollbar") |>find_elements("a") |>as.list() |>lapply(\(x) x |>elem_attrs()) elegir_activos <- mostrando |> purrr::map(~ .x$class) escondidos <- elegir_activos |> purrr::map(~ stringr::str_detect(.x, "hidden")) |>unlist() show_block <- elegir_activos |> purrr::map(~ stringr::str_detect(.x, "show_block")) |>unlist() real_mostrar <- escondidos & show_block# Si la suma es cero implica que no hay otras variantes# Las imagenes todas son de esa varianteif (sum(escondidos) ==0) { filtrando <-rep(TRUE, length(escondidos)) |> purrr::map(~list(.x) |>unlist()) } else { filtrando <- real_mostrar }#filtrando <- elegir_activos |> # purrr::map(~ stringr::str_detect(.x, "show_block")) mostrando[which(filtrando ==TRUE)] |> purrr::map(~ .x$`data-fullsizeimgsrc`) |>unlist()}extraer_info_variante <-function(producto){#- Title xxx titulo <-s(".cart-info.text-left") |>find_element("h1") |>elem_text()# Variants variante <-ss(".mr-md-3.mr-sm-1") |>lapply(\(x) x |>elem_text())# Images imagenes_url <-extrae_imagenes() # Price precio_final <-s(".cart-info.text-left") |>find_element("#var_price") |>elem_text() precio_anterior <-s(".cart-info.text-left") |>find_element("#var_market_price") |>elem_text()# Encuentra la descripcion descripcion <-s(".des-pro-sec") |>find_elements("li") |>lapply(\(x) x |>with(elem_text(x)))# Encuentra la categoria categoria <-s(".container.npdp-design") |>find_element(".breadcrumb-custom") |>find_elements("a") |>lapply(\(x) x |>elem_attr("href"))return(list(titulo = titulo,imagenes_url = imagenes_url,variante = variante,precio_final = precio_final,precio_anterior = precio_anterior,descripcion = descripcion,categoria = categoria))}# Consolida todas las URL de la pagina mostradaleer_direcciones <-function(){s(".products-grid") |>find_elements(".productImage") |>lapply(\(x) x |>find_element("a") |>elem_attr("href"))}pasar_pagina <-function(){ paginacion <-s(".pagination") |>find_elements("li") |>as.list() |>lapply(\(x) x |>elem_attrs()) |> purrr::map(~ .x$class) |>unlist()s(paste0(".", gsub("\\..$", "", gsub(" ", ".", paginacion[length(paginacion)])))) |>elem_click()}convertir_string <-function(button){sub("[.]$","",gsub("\\..$", "", gsub(" ", ".", button)))}mi_funcion <-function(listado_botones_new){cat(paste0("Aquí: ", length(listado_botones_new$iter_botones), " a leer\n"))for (btn in1:length(listado_botones_new$iter_botones)) { skip_next_loop <-FALSEcat(paste0("___Iniciando lectura del boton: ", btn, "\n"))tryCatch(expr = {# ss(paste0(".", convertir_string(listado_botones$iter_botones[btn]))) |> # as.list() |> # lapply(\(x) x |> elem_click())ss("button") |>#elem_filter(is_enabled) |> str()elem_filter(has_exact_text(listado_botones_new$iter_botones[btn])) |>lapply(\(x) x |>elem_click())Sys.sleep(0.5)#cat(paste0("", "\n")) guardar_info <-extraer_info_variante()cat(paste0("___Terminamos lectura de variantes", "\n")) info_producto[[btn]] <- guardar_info },error =function(e) {# Manejar el error aquíprint(paste("Error en la iteración", btn, ": ", e$message))# Continuar con el bucle for skip_next_loop <-TRUE } )if (skip_next_loop) {next } }return(info_producto)}otra_funcion <-function(consolidar_direcciones) { ejecutar <-list() timings <-list()for (product in1:length(consolidar_direcciones)) {tryCatch( { tictoc::tic(product)cat("Iniciamos scraping del producto: ", product, "\n")open_url(paste0("https://www.cartlow.com/", consolidar_direcciones[[product]]))Sys.sleep(1) texto_botones <-s(".cart-info.text-left") |>find_elements(".prd-condition.mb-3") |>as.list() |>lapply(\(x) x |>find_elements(".btn") |>lapply(\(x) x |>elem_text())) listado_botones_new <-list(iter_botones =unlist(texto_botones)) info_producto <-vector("list", length(listado_botones_new$iter_botones)) guardar_info <-list() ejecutar[[product]] <-mi_funcion(listado_botones_new)cat("Terminamos scraping del producto: ", product, "\n\n") tictoc::toc(log =TRUE, quiet =TRUE) },error =function(e) {cat("Error occurred while processing product", product, "\n")# You can log the error, send an email, or do something else# For example, you can log the error to a file:sink("error.log")cat("Error: ", str(e), "\n")sink() } ) } log.txt <- tictoc::tic.log(format =TRUE) log.lst <- tictoc::tic.log(format =FALSE) tictoc::tic.clearlog() timings <-unlist(lapply(log.lst, function(x) x$toc - x$tic))return(list(ejecutar = ejecutar, tiempos = timings))}calcula_cantidad_variante <-function(bd){ bd$ejecutar |>lapply(\(x) x |> purrr::map(~ (unlist(.x$variante)))) |>lapply(\(x) length(x)) |>unlist()}organizar_tiempos <-function(tabla, bd){ entregar <- tabla |> dplyr::mutate(cantidad =calcula_cantidad_variante(bd)[1:length(tabla[,1])]) names(entregar) <-c("tiempos", "cantidad") entregar}
Declaradas las funciones que vamos a usar, empecemos a ejecutar:
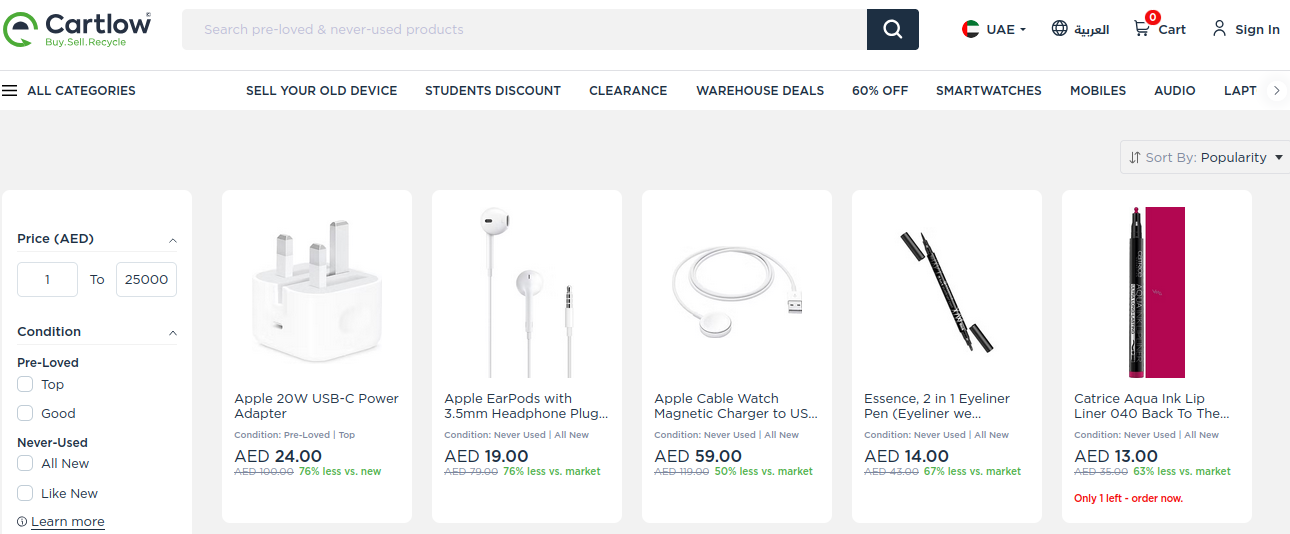
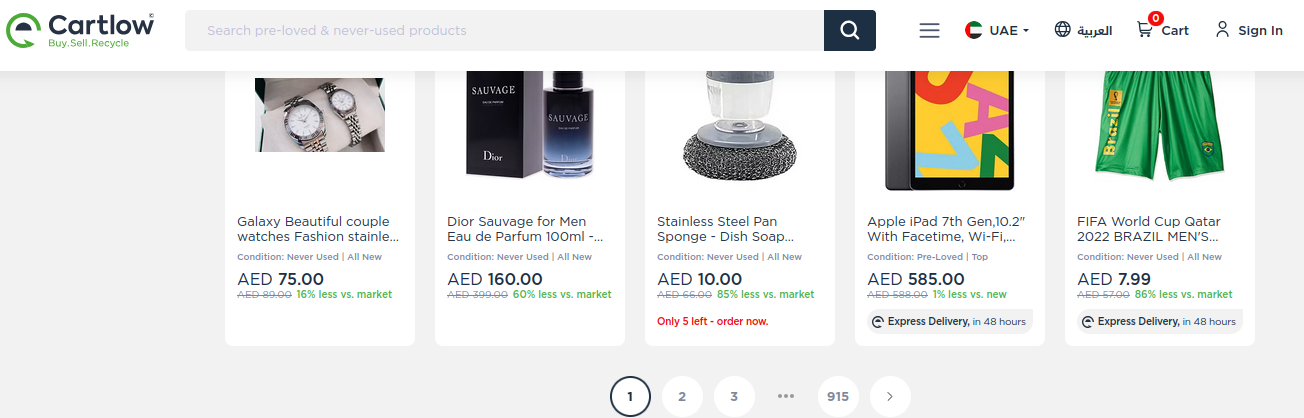
# Abrir la páginaopen_url(url)Sys.sleep(2)# Identificar cantidad de paginaspaginas <-s(".pagination") |>find_elements("li") |>lapply(\(x) x |>elem_text())paginas <-as.numeric(paginas[[length(paginas)-1]])consolidar_direcciones <-list()# Obtener URL de cada productofor (pagina in1:3) {cat(paste0("Estamos en la página: ", pagina, "\n"))# Leer las URL de las imagenes direcciones <-leer_direcciones()# Agregar las URL consolidar_direcciones <-append(consolidar_direcciones, direcciones)# Pasar a la siguiente páginapasar_pagina()cat(paste0("...pasando a la siguiente página", "\n"))Sys.sleep(1)}
Por ahora solo vamos a explorar el tiempo que tarda la lectura de datos en las primeras 3 páginas.
Aquí deberás hacer un salto de fe y creerme que la siguiente información no la inventé, sino que son los resultados del código ejecutado de manera local. Guardé los datos en 3 archivos diferentes adjuntos. Habrás notado que los dos anteriores chunks estaban programados para no ejecutarse:
Luego de revisar la cantidad de productos por página (30) y la cantidad de páginas promedio (920) podemos hacer una estimación de la cantidad de horas que podríamos tardar haciendo el ejercicio.
datos <-sample(dist_variantes$cantidad,size =920*30,replace =TRUE,prob = dist_variantes$prop)table(datos) |>data.frame() |>cbind(media = dist_variantes$media) |> dplyr::mutate(total = Freq * media *as.numeric(datos)) |> dplyr::summarise(total =sum(total)/(3600))
total
1 1453.796
Consideraciones:
Leer cada página de resultados (aproximadamente entre 915 y 925) toma unos 5 segundos. Por defecto, se muestran 30 productos en cada vista.
Identificar el número de opciones por producto (varía entre 1 y 11 según los resultados obtenidos, aunque imagino que es posible encontrar más) toma unos 20 segundos.
Identificar los datos de variantes para cada producto (depende de la conexión a Internet y el procesador, estoy trabajando localmente) toma unos 110 segundos.
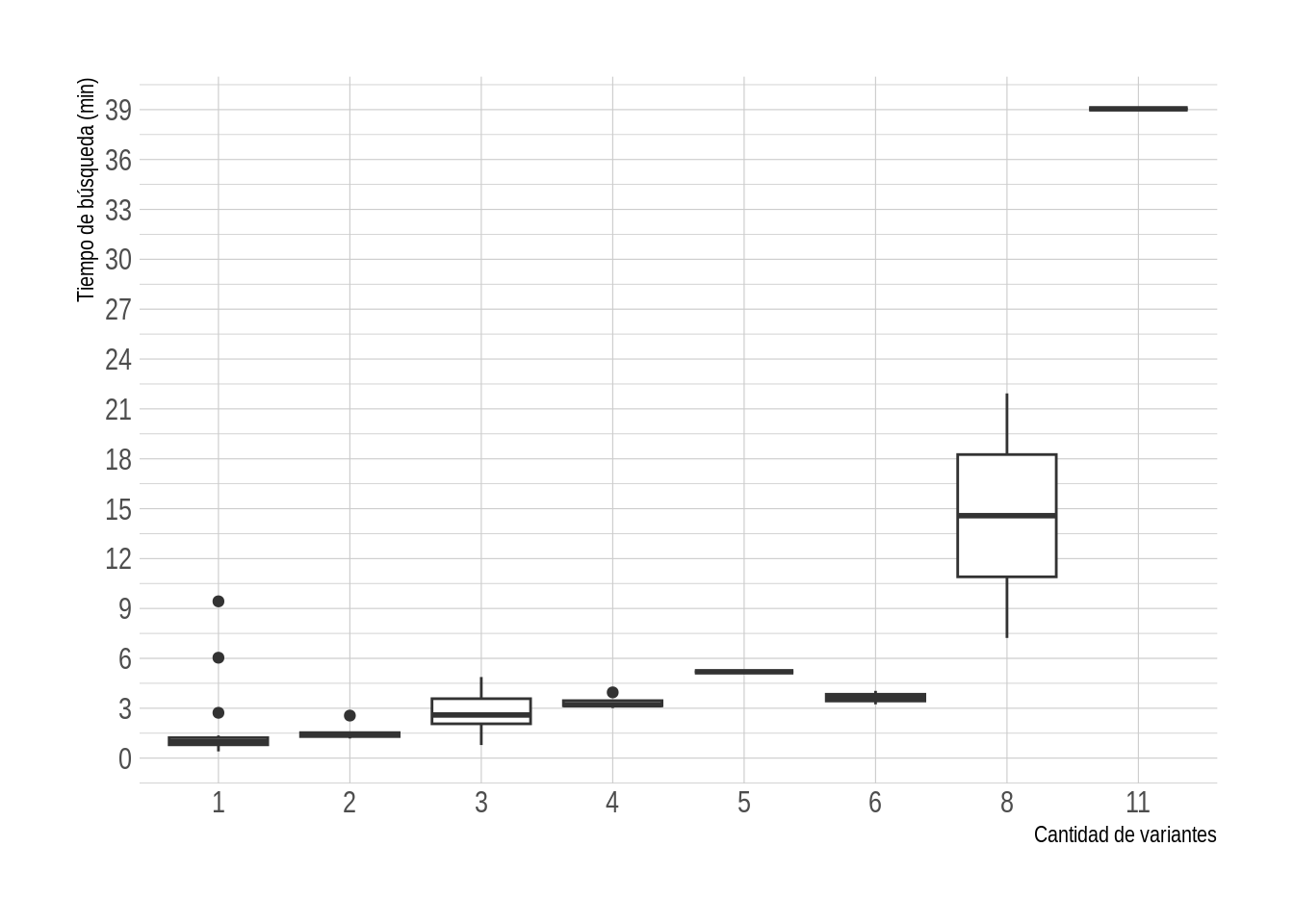
Dependiendo de lo que estés tratando de lograr con el scraping web, el tiempo de búsqueda puede aumentar significativamente, lo que está influenciado por la cantidad de opciones que tiene cada producto. Si tienes 3 opciones para “Condición”, 5 para “Color” y 3 para “Talla”, seguramente sabes que no son 11 iteraciones para realizar.
Con los datos que obtuve, se podría estimar un total de 920 páginas * 30 productos por página = 1438 horas. Hay un 47% de probabilidad de que los productos tengan solo 1 variante, un 15% para 2 y un 3%.
Es probablemente infructífero hacerlo con solo un ordenador. Debes encontrar una forma de hacerlo en paralelo.
Debes encontrar una forma de garantizar que no se repita la información en la base de datos que uses.
Ten en cuenta que tendrás que desarrollar una idea para manejar la información cuando los productos cambian en la página.
Citation
BibTeX citation:
@online{chiquito_valencia2024,
author = {Chiquito Valencia, Cristian},
title = {Shopify Scraping Con {R}},
date = {2024-12-19},
url = {https://cchiquitovalencia.github.io/posts/2024-12-19-cartlow_scraping/},
langid = {en}
}